Scaling Kubernetes Nodes Effectively with Karpenter
Learn how Karpenter automates node provisioning and consolidation, reducing infrastructure costs and improving resource utilization compared to traditional cluster autoscalers.

#Introduction
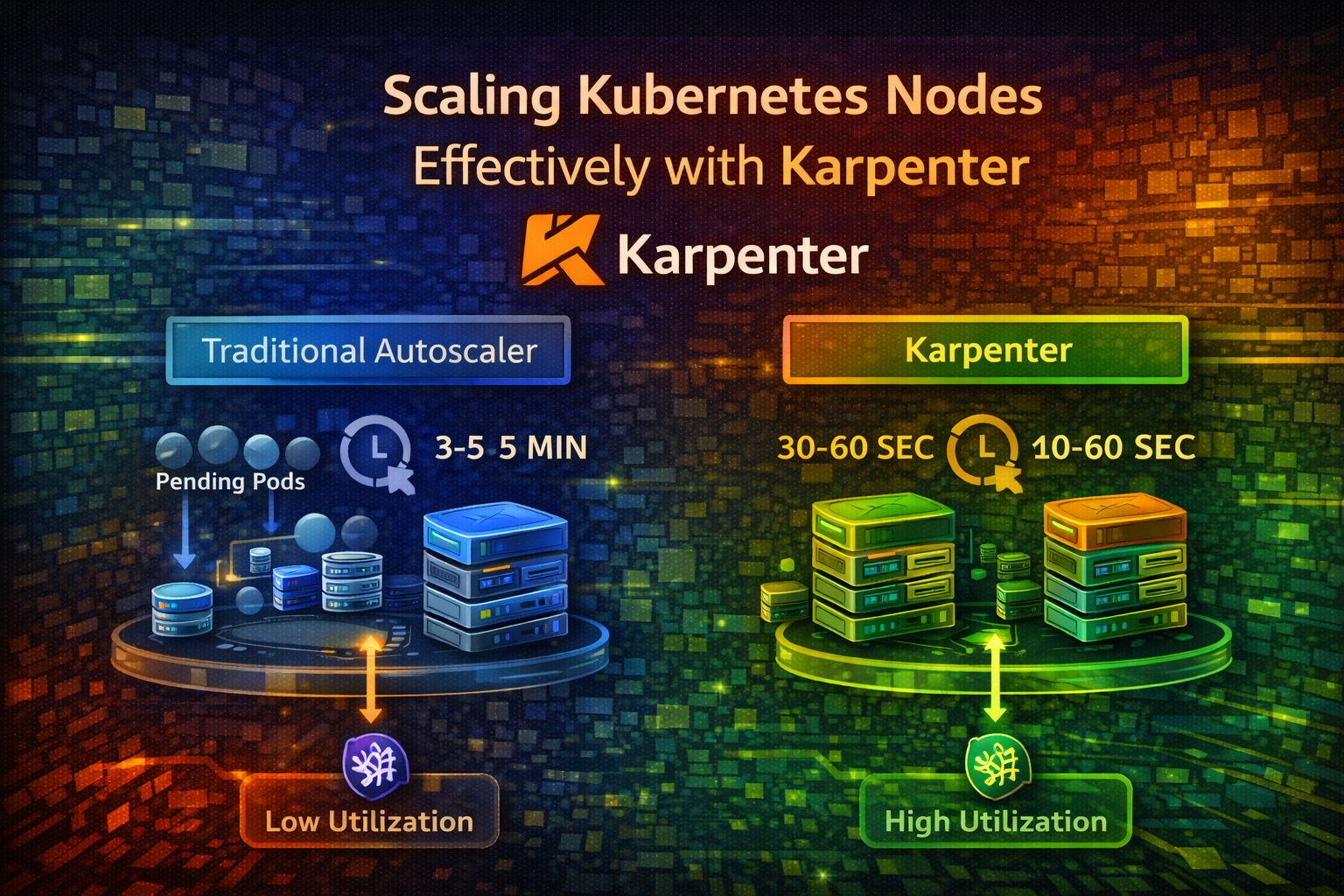
Your Kubernetes cluster is running smoothly until a deployment scales up and suddenly, pods are stuck in Pending state. There aren't enough nodes to run them. You wait for the cluster autoscaler to notice, provision new nodes, and boot them up. This takes 3-5 minutes. Your users wait.
Meanwhile, you have other nodes running at 10% utilization, wasting money. The cluster autoscaler doesn't consolidate them because it's conservative—it doesn't want to disrupt workloads.
Karpenter solves both problems. It provisions nodes in seconds instead of minutes and actively consolidates underutilized nodes, reducing costs by 30-50% compared to traditional autoscalers.
In this article, we'll explore why node scaling matters, how Karpenter works, and how to implement it for your cluster.
#The Problem with Traditional Cluster Autoscalers
#How Cluster Autoscaler Works
Kubernetes' default cluster autoscaler watches for pending pods and provisions new nodes. Here's the flow:
- Pod is created but can't be scheduled (no nodes have capacity)
- Cluster autoscaler detects pending pods
- Autoscaler provisions a new node from your cloud provider
- Node boots up and joins the cluster (3-5 minutes)
- Pod is scheduled on the new node
This works, but it's slow and inefficient.
#The Inefficiency Problem
Cluster autoscaler has several limitations:
Slow Provisioning: Nodes take 3-5 minutes to boot. During this time, pods wait and users experience latency.
Poor Consolidation: Cluster autoscaler rarely removes nodes. It's conservative because removing a node might disrupt workloads. Result: underutilized nodes waste money.
Bin Packing Issues: Cluster autoscaler doesn't optimize how pods are packed onto nodes. You might have 10 nodes at 40% utilization instead of 7 nodes at 60% utilization.
Limited Node Types: Cluster autoscaler works with node groups you pre-define. If you need a different node type, you have to manually create a new node group.
No Cost Optimization: Cluster autoscaler doesn't consider node costs. It might provision expensive nodes when cheaper options exist.
#Real-World Impact
Consider a typical scenario:
- You have 10 nodes running at 30% average utilization
- Monthly cost: $5,000 (assuming $500/node)
- Cluster autoscaler doesn't consolidate because it's conservative
- You're wasting $3,500/month on underutilized capacity
With Karpenter, you might consolidate to 7 nodes at 45% utilization, saving $1,500/month. Over a year, that's $18,000 in savings.
#How Karpenter Works
#The Karpenter Architecture
Karpenter is a node autoscaler built for Kubernetes. It watches for pending pods and provisions nodes in seconds. It also actively consolidates underutilized nodes.
Here's the flow:
- Pod Pending: A pod can't be scheduled due to insufficient capacity
- Karpenter Detects: Karpenter's controller watches for pending pods
- Node Provisioning: Karpenter provisions a node from your cloud provider (AWS, Azure, GCP)
- Fast Boot: Nodes boot in 30-60 seconds (vs 3-5 minutes for traditional autoscalers)
- Pod Scheduled: Pod is scheduled on the new node
- Consolidation: Karpenter continuously monitors node utilization and removes underutilized nodes
Karpenter is fundamentally different from cluster autoscaler: it's proactive, not reactive.
#Karpenter vs Cluster Autoscaler
| Aspect | Cluster Autoscaler | Karpenter |
|---|---|---|
| Provisioning Speed | 3-5 minutes | 30-60 seconds |
| Consolidation | Rare, conservative | Aggressive, continuous |
| Node Type Selection | Pre-defined groups | Dynamic, cost-optimized |
| Cost Optimization | No | Yes |
| Bin Packing | Basic | Advanced |
| Multi-Cloud | Limited | AWS, Azure, GCP |
Karpenter is designed for modern, dynamic workloads where speed and cost matter.
#Fundamental Concepts
#Provisioners
A Provisioner is a Karpenter resource that defines how nodes should be provisioned. It specifies:
- Which cloud provider to use
- Node types and sizes to consider
- Constraints (CPU, memory, zones, etc.)
- Consolidation behavior
- TTL (time to live) for nodes
Think of a Provisioner as a template for node creation.
#Consolidation
Consolidation is Karpenter's killer feature. It continuously monitors node utilization and removes underutilized nodes by:
- Identifying nodes that are underutilized
- Evicting pods from those nodes
- Scheduling pods on other nodes
- Removing the empty nodes
This happens automatically and continuously, keeping your cluster lean.
#Deprovisioning
Deprovisioning is the process of removing nodes. Karpenter deprovisions nodes when:
- They're underutilized (consolidation)
- They've exceeded their TTL (time to live)
- They're empty and not needed
- A more cost-effective node type is available
#Drift
Drift occurs when a node's configuration doesn't match the Provisioner's specification. For example, if you update a Provisioner to use a different instance type, existing nodes are now "drifted." Karpenter can automatically replace drifted nodes.
#Getting Started: Basic Setup
#Prerequisites
- Kubernetes 1.19+ cluster
- AWS, Azure, or GCP account
- Helm installed
- kubectl configured
#Install Karpenter
Install Karpenter using Helm:
helm repo add karpenter https://charts.karpenter.sh
helm repo updateCreate a namespace and install Karpenter:
kubectl create namespace karpenter
helm install karpenter karpenter/karpenter \
--namespace karpenter \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=arn:aws:iam::ACCOUNT_ID:role/KarpenterControllerRole \
--set settings.aws.clusterName=my-clusterImportant
Karpenter needs IAM permissions to provision nodes. Set up the KarpenterControllerRole with appropriate permissions before installing.
Verify Karpenter is running:
kubectl get pods -n karpenter
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter -f#Create a Provisioner
A Provisioner tells Karpenter how to provision nodes. Here's a basic example:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
# Requirements for nodes
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "t3.xlarge"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a", "us-east-1b"]
# Consolidation settings
consolidation:
enabled: true
# TTL for nodes (24 hours)
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 86400
# Limits
limits:
resources:
cpu: 1000
memory: 1000Gi
# Provider (AWS)
provider:
subnetName: my-subnet
securityGroupName: my-security-group
tags:
Environment: productionThis Provisioner:
- Uses on-demand instances (not spot)
- Provisions t3 instances (medium, large, xlarge)
- Enables consolidation
- Removes empty nodes after 30 seconds
- Removes nodes after 24 hours (forces refresh)
- Limits total resources to 1000 CPU and 1000Gi memory
#Deploy a Test Workload
Create a deployment to test Karpenter:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app
spec:
replicas: 5
selector:
matchLabels:
app: test-app
template:
metadata:
labels:
app: test-app
spec:
containers:
- name: app
image: nginx:latest
resources:
requests:
cpu: 500m
memory: 256Mi
limits:
cpu: 1000m
memory: 512MiDeploy it:
kubectl apply -f test-app.yamlWatch Karpenter provision nodes:
kubectl get nodes --watch
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter -fYou should see new nodes provisioned within 30-60 seconds. Much faster than cluster autoscaler.
#Practical Scenarios
#Scenario 1: Cost Optimization with Spot Instances
Use cheaper spot instances for non-critical workloads:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: spot
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "m5.large", "m5.xlarge"]
consolidation:
enabled: true
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 604800
provider:
subnetName: my-subnet
securityGroupName: my-security-groupThis Provisioner prefers spot instances (cheaper) but falls back to on-demand if spot isn't available. Karpenter automatically handles spot interruptions by evicting pods and rescheduling them.
#Scenario 2: Multiple Provisioners for Different Workloads
Create separate Provisioners for different workload types:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge"]
- key: karpenter.k8s.aws/instance-gpu-count
operator: In
values: ["1", "2"]
consolidation:
enabled: false
ttlSecondsAfterEmpty: 30
provider:
subnetName: my-subnet
securityGroupName: my-security-group
tags:
WorkloadType: gpuThis Provisioner handles GPU workloads. Pods requesting GPUs are scheduled on GPU nodes. CPU-only pods use the default Provisioner.
#Scenario 3: Zone Distribution
Spread nodes across multiple zones for high availability:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: multi-zone
spec:
requirements:
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a", "us-east-1b", "us-east-1c"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large"]
consolidation:
enabled: true
ttlSecondsAfterEmpty: 30
provider:
subnetName: my-subnet
securityGroupName: my-security-groupKarpenter distributes nodes across zones, improving fault tolerance.
#Scenario 4: Consolidation Tuning
Control how aggressively Karpenter consolidates nodes:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: aggressive-consolidation
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "t3.xlarge"]
consolidation:
enabled: true
# Remove empty nodes immediately
ttlSecondsAfterEmpty: 0
# Refresh nodes every 7 days
ttlSecondsUntilExpired: 604800
provider:
subnetName: my-subnet
securityGroupName: my-security-groupThis aggressively consolidates nodes, removing empty nodes immediately. Use this for cost-sensitive environments.
#Advanced Configuration
#Pod Disruption Budgets
Protect critical workloads during consolidation:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: critical-app-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: critical-appThis ensures at least 2 pods of critical-app are always running. Karpenter won't consolidate nodes if it would violate this budget.
#Taints and Tolerations
Use taints to restrict which pods can run on certain nodes:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: batch-processing
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["c5.large", "c5.xlarge"]
taints:
- key: workload-type
value: batch
effect: NoSchedule
consolidation:
enabled: true
provider:
subnetName: my-subnet
securityGroupName: my-security-groupOnly pods with matching tolerations can run on these nodes:
apiVersion: v1
kind: Pod
metadata:
name: batch-job
spec:
tolerations:
- key: workload-type
operator: Equal
value: batch
effect: NoSchedule
containers:
- name: job
image: batch-processor:latest#Monitoring Karpenter
Monitor Karpenter's behavior with Prometheus metrics:
# Nodes provisioned
increase(karpenter_nodes_allocatable[5m])
# Nodes consolidated
increase(karpenter_nodes_consolidated[5m])
# Pending pods
karpenter_pods_pending
# Provisioning duration
histogram_quantile(0.99, rate(karpenter_provisioning_duration_seconds_bucket[5m]))Set up dashboards to visualize these metrics.
#Common Mistakes and Pitfalls
#Mistake 1: Not Setting Resource Requests
If pods don't have resource requests, Karpenter can't calculate node capacity. Pods might be scheduled on nodes that don't have enough resources.
Better: Always set resource requests and limits:
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi#Mistake 2: Ignoring Pod Disruption Budgets
Without PodDisruptionBudgets, Karpenter might consolidate nodes and disrupt critical workloads.
Better: Define PodDisruptionBudgets for critical applications.
#Mistake 3: Setting TTL Too Low
If ttlSecondsUntilExpired is too low, nodes are constantly replaced, causing unnecessary disruption.
Better: Set TTL to 24-48 hours. This balances freshness with stability.
#Mistake 4: Over-Consolidating
Aggressive consolidation saves money but can cause latency spikes when pods are evicted and rescheduled.
Better: Tune consolidation based on your workload. For latency-sensitive applications, be more conservative.
#Mistake 5: Not Monitoring Karpenter
Karpenter is another component that can fail. If it crashes, node scaling stops.
Better: Monitor Karpenter's health, set up alerts, and ensure it's highly available.
#Best Practices
#1. Start with Conservative Settings
Don't enable aggressive consolidation immediately. Start with:
consolidation:
enabled: true
ttlSecondsAfterEmpty: 300
ttlSecondsUntilExpired: 604800Monitor behavior and adjust based on real-world results.
#2. Use Multiple Provisioners
Create separate Provisioners for different workload types:
- General workloads (default)
- GPU workloads
- Batch processing
- Memory-intensive workloads
This gives you fine-grained control over node provisioning.
#3. Combine with Pod Disruption Budgets
Protect critical workloads with PodDisruptionBudgets. This prevents Karpenter from disrupting them during consolidation.
#4. Monitor Cost Savings
Track how much you're saving with Karpenter:
# Before Karpenter: 10 nodes × $500/month = $5,000
# After Karpenter: 7 nodes × $500/month = $3,500
# Savings: $1,500/month = $18,000/year#5. Test Consolidation Behavior
Before deploying to production, test how Karpenter consolidates nodes:
- Deploy workloads and watch nodes scale up
- Remove workloads and watch nodes consolidate
- Verify pods aren't disrupted unexpectedly
#6. Use Spot Instances for Non-Critical Workloads
Spot instances are 70-90% cheaper than on-demand. Use them for:
- Batch processing
- Development/testing
- Non-critical background jobs
Karpenter handles spot interruptions automatically.
#7. Set Resource Limits
Prevent runaway provisioning by setting limits:
limits:
resources:
cpu: 1000
memory: 1000GiThis prevents Karpenter from provisioning more than 1000 CPU cores or 1000Gi memory.
#When NOT to Use Karpenter
#Karpenter Isn't Ideal When:
- You have a small, static cluster: Karpenter's benefits are most visible with dynamic workloads
- You need guaranteed node types: Karpenter dynamically selects node types; if you need specific hardware, use traditional autoscalers
- You're not on AWS, Azure, or GCP: Karpenter supports these clouds; other platforms need different solutions
- You have very strict compliance requirements: Karpenter's dynamic provisioning might not fit rigid compliance frameworks
#Conclusion
Karpenter transforms how you scale Kubernetes clusters. Instead of waiting 3-5 minutes for nodes to boot, you get nodes in 30-60 seconds. Instead of wasting money on underutilized nodes, Karpenter actively consolidates them.
The fundamental insight: node scaling should be fast, efficient, and cost-aware. Karpenter delivers all three.
Start with a basic Provisioner for general workloads. Add specialized Provisioners for GPU, batch processing, or other workload types. Enable consolidation and watch your costs drop. Monitor everything and adjust based on real-world behavior.
Your cluster will be faster, cheaper, and more efficient.
#Next Steps
- Install Karpenter in your Kubernetes cluster
- Create a basic Provisioner for general workloads
- Deploy test workloads and watch nodes scale
- Monitor consolidation and verify pods aren't disrupted
- Add specialized Provisioners for different workload types
- Track cost savings and celebrate the wins
Start simple, test thoroughly, and scale intelligently.