From Data Warehouse to Modern Data Lakehouse - Architecture Evolution & Separation of Concerns
Explore the evolution from traditional data warehouses to modern data lakehouses. Learn how decoupled storage, open table formats, and query engines transform data architecture with Apache Iceberg, Nessie, and S3-based storage.

#Introduction
Data architecture has undergone a fundamental transformation over the past decade. The traditional data warehouse—a monolithic, tightly coupled system optimized for structured analytics—is giving way to the modern data lakehouse: a decoupled, cloud-native architecture that separates storage, compute, and metadata management.
This shift isn't just about technology choices. It's about rethinking how data flows through organizations. Instead of forcing all data into rigid schemas before storage, modern lakehouses store raw data in open formats, apply schema-on-read logic, and let multiple query engines operate independently on the same data.
In this guide, we'll trace the evolution from classic data warehouses to modern lakehouses, understand why separation of concerns matters, and explore the technologies enabling this transformation.
#The Classic Data Warehouse: Tightly Coupled Architecture
#How Traditional Data Warehouses Work
Classic data warehouses like Teradata, Netezza, or on-premises Redshift follow a monolithic design:
Raw Data → ETL (Extract, Transform, Load) → Warehouse Storage → Query Engine → AnalyticsEverything is integrated into a single system:
- Storage: Proprietary columnar format, tightly coupled to the query engine
- Compute: Fixed resources allocated to the warehouse
- Metadata: Managed internally by the warehouse
- Query Engine: Single SQL runtime, optimized for the warehouse's storage format
#Characteristics of Traditional Warehouses
Strengths:
- Predictable performance for structured queries
- Strong ACID guarantees
- Mature tooling and operational practices
- Schema-on-write ensures data quality upfront
Limitations:
- Expensive to scale (compute and storage bundled)
- Difficult to support multiple query patterns (SQL, ML, streaming)
- Vendor lock-in with proprietary formats
- Slow to adapt to new data types (unstructured, semi-structured)
- ETL bottlenecks during data ingestion
#The ETL Bottleneck
Traditional ETL pipelines are rigid and resource-intensive:
Data Source → Transformation Logic → Validation → Load to WarehouseEvery data change requires:
- Extracting from source systems
- Transforming to warehouse schema
- Validating against business rules
- Loading into warehouse storage
This process is slow, expensive, and creates a single point of failure. If transformation logic changes, you must re-process historical data.
#The Data Lake Experiment: Storage Without Structure
In the early 2010s, organizations tried a different approach: dump everything into cheap object storage (S3, HDFS) and figure out structure later.
Raw Data → S3 (Parquet/ORC) → Spark/Hadoop → AnalyticsThe promise: Unlimited scalability, schema-on-read flexibility, lower costs.
The reality: Data swamps.
Without structure, data lakes became:
- Difficult to discover (what data exists?)
- Hard to govern (who owns what?)
- Slow to query (no optimization)
- Unreliable (no ACID guarantees)
- Fragmented (multiple incompatible formats)
The data lake solved the storage problem but created new problems around metadata, governance, and query performance.
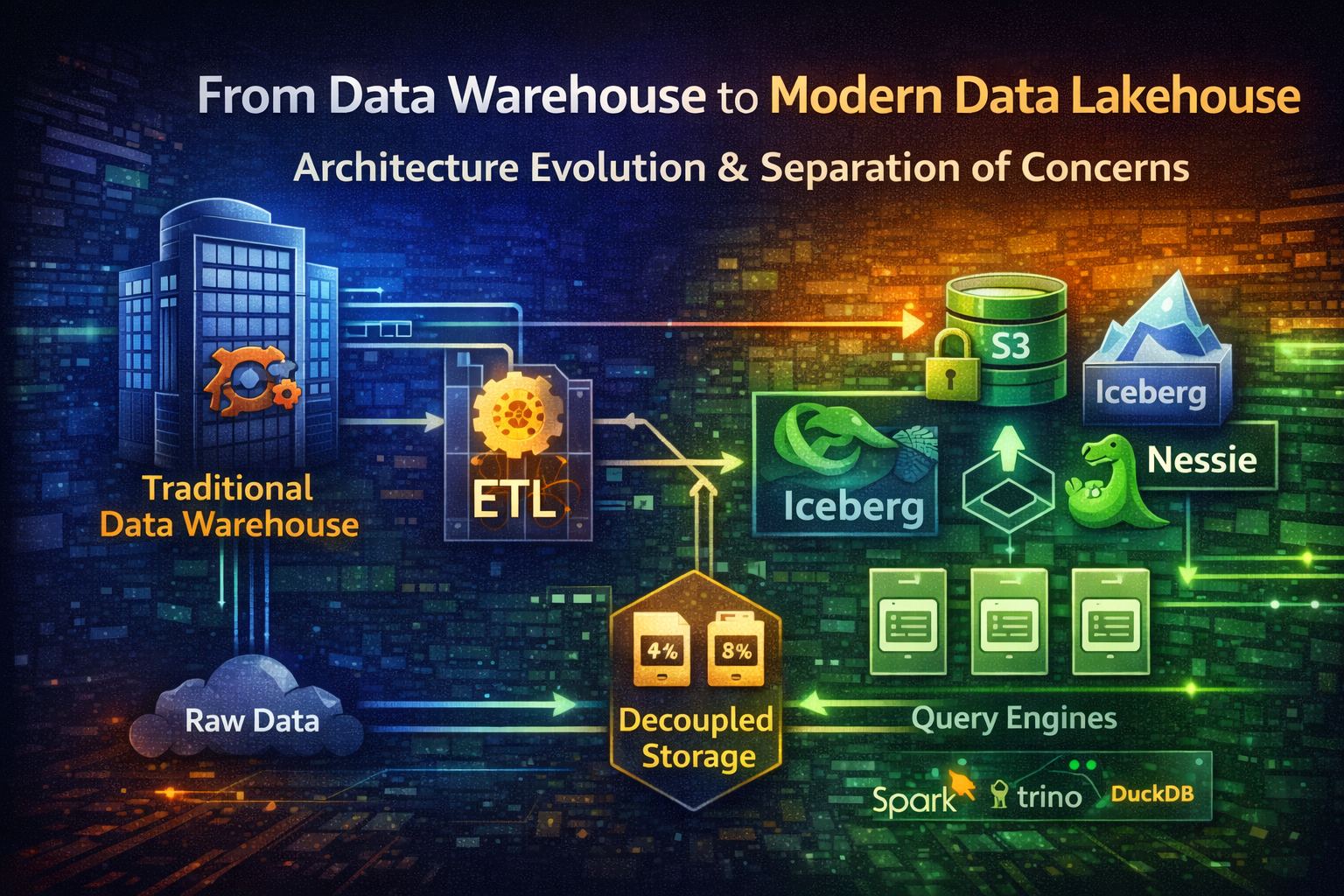
#Modern Data Lakehouse: Separation of Concerns
The modern data lakehouse combines the best of both worlds: the scalability and flexibility of data lakes with the structure and reliability of data warehouses.
The key innovation: decoupling storage, compute, and metadata.
┌─────────────────────────────────────────────────────────────┐
│ Query Layer │
│ (Trino, Spark, DuckDB, Presto, Athena) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Open Table Format Layer │
│ (Apache Iceberg, Delta Lake, Apache Hudi) │
│ + Metadata Management (Nessie, Polaris) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Storage Layer │
│ (S3, GCS, Azure Blob Storage) │
│ Format: Parquet, Avro, ORC │
└─────────────────────────────────────────────────────────────┘#Layer 1: Storage (Decoupled)
Modern lakehouses use cloud object storage as the foundation:
Why S3 (or equivalent)?
- Unlimited scalability
- Pay-per-use pricing
- Durability and availability
- Works with any compute engine
Data Formats:
# Parquet structure
[Row Group 1]
├── Column 1 (compressed)
├── Column 2 (compressed)
└── Column 3 (compressed)
[Row Group 2]
├── Column 1 (compressed)
├── Column 2 (compressed)
└── Column 3 (compressed)Parquet is columnar, compressed, and schema-aware. Perfect for analytics.
# Avro structure
{
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": "string"}
]
}Avro is row-based, schema-versioned, and ideal for streaming and event data.
Both formats are open, language-agnostic, and supported by multiple tools.
#Layer 2: Open Table Format (Metadata Management)
Raw Parquet files in S3 lack structure. Open table formats add the missing layer: metadata management, ACID transactions, and schema evolution.
#Apache Iceberg
Iceberg is a table format that sits on top of object storage:
S3 Bucket
├── data/
│ ├── 00001-abc.parquet
│ ├── 00002-def.parquet
│ └── 00003-ghi.parquet
├── metadata/
│ ├── v1.metadata.json
│ ├── v2.metadata.json
│ └── snap-123.avro
└── metadata.json (current version pointer)Iceberg tracks:
- Schema evolution
- Snapshots (versions of the table)
- Partition information
- File statistics
- Transaction history
Example: Creating an Iceberg table
CREATE TABLE users (
id INT,
name STRING,
email STRING,
created_at TIMESTAMP
)
USING iceberg
PARTITIONED BY (year(created_at))
LOCATION 's3://my-bucket/users';Time Travel: Query Historical Data
-- Query table as it was 1 hour ago
SELECT * FROM users
FOR SYSTEM_TIME AS OF timestamp_sub(now(), interval 1 hour);
-- Query specific snapshot
SELECT * FROM users
VERSION AS OF 'snapshot-id-123';This is powerful for debugging, auditing, and recovery.
#Nessie: Git-Like Version Control for Data
Nessie adds Git-like semantics to data tables:
Main Branch
├── Commit 1: "Add user table"
├── Commit 2: "Add email column"
└── Commit 3: "Fix data quality issue"
Feature Branch (dev)
├── Commit 1: "Add phone column"
└── Commit 2: "Update schema"Why Git-like versioning for data?
- Branches: Experiment with schema changes without affecting production
- Commits: Track who changed what and when
- Merges: Combine changes from multiple branches
- Rollback: Revert to previous state if something breaks
Example: Nessie with Iceberg
# Create feature branch
nessie branch create feature/add-phone-column
# Switch to branch
nessie checkout feature/add-phone-column
# Make changes (add column, update data)
# Commit changes
nessie commit -m "Add phone column to users table"
# Merge back to main
nessie checkout main
nessie merge feature/add-phone-columnThis enables data teams to work like software engineers: experiment safely, review changes, and merge with confidence.
#Layer 3: Query Engines (Decoupled Compute)
The lakehouse doesn't mandate a single query engine. Multiple engines can query the same data:
Apache Iceberg Tables in S3
├── Trino (distributed SQL)
├── Spark (batch & streaming)
├── DuckDB (analytical queries)
├── Presto (interactive queries)
└── Athena (serverless SQL)Each engine has different strengths:
- Trino: Distributed SQL across multiple data sources
- Spark: Large-scale batch processing and ML
- DuckDB: Fast analytical queries on single machines
- Athena: Serverless, pay-per-query model
- Flink: Real-time streaming analytics
Example: Same data, different engines
-- Trino: Interactive queries
SELECT user_id, COUNT(*) as events
FROM events
WHERE date >= '2026-01-01'
GROUP BY user_id
LIMIT 100;# Spark: Batch processing
df = spark.read.format("iceberg").load("s3://bucket/events")
result = df.filter(col("date") >= "2026-01-01") \
.groupBy("user_id") \
.count() \
.limit(100)
result.show()-- DuckDB: Local analytical queries
SELECT user_id, COUNT(*) as events
FROM read_parquet('s3://bucket/events/*.parquet')
WHERE date >= '2026-01-01'
GROUP BY user_id
LIMIT 100;Same data, different tools for different use cases.
#Separation of Concerns: Why It Matters
#1. Storage & Compute Decoupling
Traditional warehouse:
Compute Resources (Fixed)
↓
Storage (Bundled)You pay for compute even when idle. Scaling requires provisioning more resources.
Modern lakehouse:
Compute Resources (Elastic)
↓
Storage (Shared)
↓
Multiple Query EnginesScale compute independently from storage. Pay only for what you use.
#2. Multiple Query Patterns
Traditional warehouse: One SQL engine, one way to query.
Modern lakehouse: Choose the right tool for the job.
Data Scientists → Spark (ML, Python)
Analytics Team → Trino (Interactive SQL)
Real-time Dashboards → Flink (Streaming)
Ad-hoc Queries → DuckDB (Local)#3. Schema Evolution Without Reprocessing
Traditional warehouse: Schema changes require ETL reprocessing.
Modern lakehouse: Iceberg handles schema evolution transparently.
-- Add new column
ALTER TABLE users ADD COLUMN phone STRING;
-- Old data automatically has NULL for phone
-- New data includes phone value
-- No reprocessing needed#4. Data Governance & Lineage
Nessie provides Git-like audit trails:
nessie log --table users
# Shows who changed what, when, and whyThis is critical for compliance (GDPR, HIPAA) and debugging.
#Modern ETL: From Batch to Streaming
#Traditional ETL: Batch-Oriented
Scheduled Job → Extract → Transform → Load → WarehouseRuns nightly, processes all data, updates warehouse.
Problems:
- Latency (data is hours old)
- Resource spikes during batch windows
- Difficult to handle late-arriving data
- All-or-nothing: if transformation fails, entire batch fails
#Modern ELT: Extract, Load, Transform
Data Source → S3 (Raw) → Transform (On-Demand) → AnalyticsLoad raw data first, transform later.
Benefits:
- Lower latency (data available immediately)
- Flexible transformation (change logic without reprocessing)
- Resilient (raw data preserved)
- Supports streaming and batch
#UI-Based ETL: Apache NiFi
For teams without strong engineering resources, UI-based ETL tools like Apache NiFi provide visual data pipeline design:
┌──────────────┐
│ Data Source │
└──────┬───────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Extract) │
└──────┬───────────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Transform) │
└──────┬───────────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Load to S3) │
└──────────────────┘NiFi advantages:
- Visual pipeline design (no coding required)
- Built-in error handling and retry logic
- Data provenance tracking
- Supports multiple data sources and formats
- Scales horizontally
Example: NiFi Flow
GetFile (Read from /data)
↓
UpdateAttribute (Add metadata)
↓
ConvertRecord (CSV → Parquet)
↓
PutS3Object (Write to S3)
↓
PublishKafka (Notify downstream)Each processor is a reusable component. Chain them together to build complex pipelines without code.
#Real-World Architecture: Putting It Together
Here's a complete modern lakehouse architecture:
┌─────────────────────────────────────────────────────────────┐
│ Data Sources │
│ (Databases, APIs, Logs, Streaming) │
└────────────────────┬────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────────┐
│ Ingestion Layer (NiFi) │
│ • Extract from sources │
│ • Minimal transformation │
│ • Load to S3 (raw zone) │
└────────────────────┬────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────────┐
│ Storage Layer (S3) │
│ • Raw Zone (Parquet/Avro) │
│ • Processed Zone (Iceberg Tables) │
│ • Curated Zone (Business-ready tables) │
└────────────────────┬────────────────────────────────────────┘
│
┌────────────┼────────────┐
↓ ↓ ↓
┌──────────────┐ ┌──────────┐ ┌──────────┐
│ Spark Jobs │ │ Trino │ │ DuckDB │
│ (Batch) │ │ (SQL) │ │ (Local) │
└──────┬───────┘ └────┬─────┘ └────┬─────┘
│ │ │
└──────────────┼────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Metadata Layer (Nessie + Iceberg) │
│ • Schema management │
│ • Version control │
│ • Time travel queries │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Analytics & BI │
│ (Dashboards, Reports, ML Models) │
└─────────────────────────────────────────────────────────────┘#Common Mistakes & Pitfalls
#Mistake 1: Treating Lakehouse Like a Data Lake
The problem: Dump data into S3 without table format or governance.
Why it happens: Teams skip the open table format layer to save complexity.
How to avoid it:
- Use Iceberg or Delta Lake from day one
- Implement schema validation
- Set up data governance policies
- Use Nessie for version control
#Mistake 2: Ignoring Partition Strategy
The problem: Queries scan entire datasets, performance degrades.
Why it happens: Partition strategy is an afterthought.
How to avoid it:
- Partition by frequently filtered columns (date, region, customer_id)
- Use time-based partitions for time-series data
- Monitor partition sizes (aim for 100MB-1GB per partition)
CREATE TABLE events (
event_id INT,
user_id INT,
event_type STRING,
timestamp TIMESTAMP
)
USING iceberg
PARTITIONED BY (year(timestamp), month(timestamp))
LOCATION 's3://bucket/events';#Mistake 3: Not Monitoring Query Performance
The problem: Queries slow down over time as data grows.
Why it happens: No performance monitoring or optimization.
How to avoid it:
- Monitor query execution times
- Track data skew (uneven partition sizes)
- Use table statistics for query optimization
- Compact small files regularly
#Mistake 4: Mixing Raw and Processed Data
The problem: Raw data gets modified, breaking downstream pipelines.
Why it happens: No clear data zones or governance.
How to avoid it:
- Separate raw, processed, and curated zones
- Make raw zone immutable
- Use Iceberg snapshots for reproducibility
#Mistake 5: Underestimating Operational Complexity
The problem: Lakehouse requires more operational expertise than traditional warehouse.
Why it happens: Teams underestimate the learning curve.
How to avoid it:
- Invest in training and documentation
- Start with a pilot project
- Build runbooks for common operations
- Monitor metadata layer health
#Best Practices for Modern Lakehouses
#1. Implement Data Zones
s3://data-lake/
├── raw/ (Immutable, as-is from source)
├── processed/ (Cleaned, validated, Iceberg tables)
└── curated/ (Business-ready, optimized)Each zone has different governance rules and access patterns.
#2. Use Iceberg for All Tables
-- Good
CREATE TABLE users USING iceberg ...
-- Avoid
CREATE TABLE users USING parquet ...Iceberg provides ACID guarantees, schema evolution, and time travel.
#3. Implement Schema Registry
{
"subject": "users-value",
"version": 1,
"schema": {
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"}
]
}
}Centralize schema management to prevent incompatibilities.
#4. Monitor Data Quality
# Check for nulls in critical columns
assert df.filter(col("user_id").isNull()).count() == 0
# Check for duplicates
assert df.count() == df.dropDuplicates(["user_id"]).count()
# Check for data freshness
latest_date = df.agg(max("created_at")).collect()[0][0]
assert (datetime.now() - latest_date).days < 1Automate data quality checks in your pipelines.
#5. Use Nessie for Experimentation
# Create isolated branch for experiments
nessie branch create experiment/new-schema
# Make changes without affecting production
# Test thoroughly
# Merge only when confident
nessie merge experiment/new-schemaBranches enable safe experimentation and rollback.
#When to Choose Lakehouse vs. Traditional Warehouse
Choose lakehouse if:
- You need to support multiple query patterns (SQL, ML, streaming)
- Data volume is large and growing rapidly
- You want to avoid vendor lock-in
- You need schema flexibility
- You have multi-cloud requirements
Choose traditional warehouse if:
- Data volume is small (< 1TB)
- You need predictable performance
- Your team lacks data engineering expertise
- You have simple, structured analytics needs
- You prefer managed services with minimal operations
#Conclusion
The shift from traditional data warehouses to modern lakehouses represents a fundamental rethinking of data architecture. By decoupling storage, compute, and metadata, lakehouses provide flexibility, scalability, and cost efficiency that monolithic warehouses cannot match.
The key technologies enabling this transformation:
- Apache Iceberg: Open table format with ACID guarantees and time travel
- Nessie: Git-like version control for data
- S3 + Parquet/Avro: Scalable, open storage formats
- Multiple query engines: Choose the right tool for each workload
- Apache NiFi: Visual ETL for non-engineers
The journey from warehouse to lakehouse isn't just a technology upgrade—it's a shift toward more flexible, collaborative, and scalable data infrastructure. Start with a pilot project, invest in team training, and gradually migrate workloads as your team gains confidence.
The future of data architecture is decoupled, open, and collaborative. The lakehouse is here.