Scaling Node Kubernetes Secara Efektif dengan Karpenter
Pelajari bagaimana Karpenter mengotomatisasi node provisioning dan consolidation, mengurangi infrastructure costs dan meningkatkan resource utilization dibandingkan traditional cluster autoscalers.

#Pengenalan
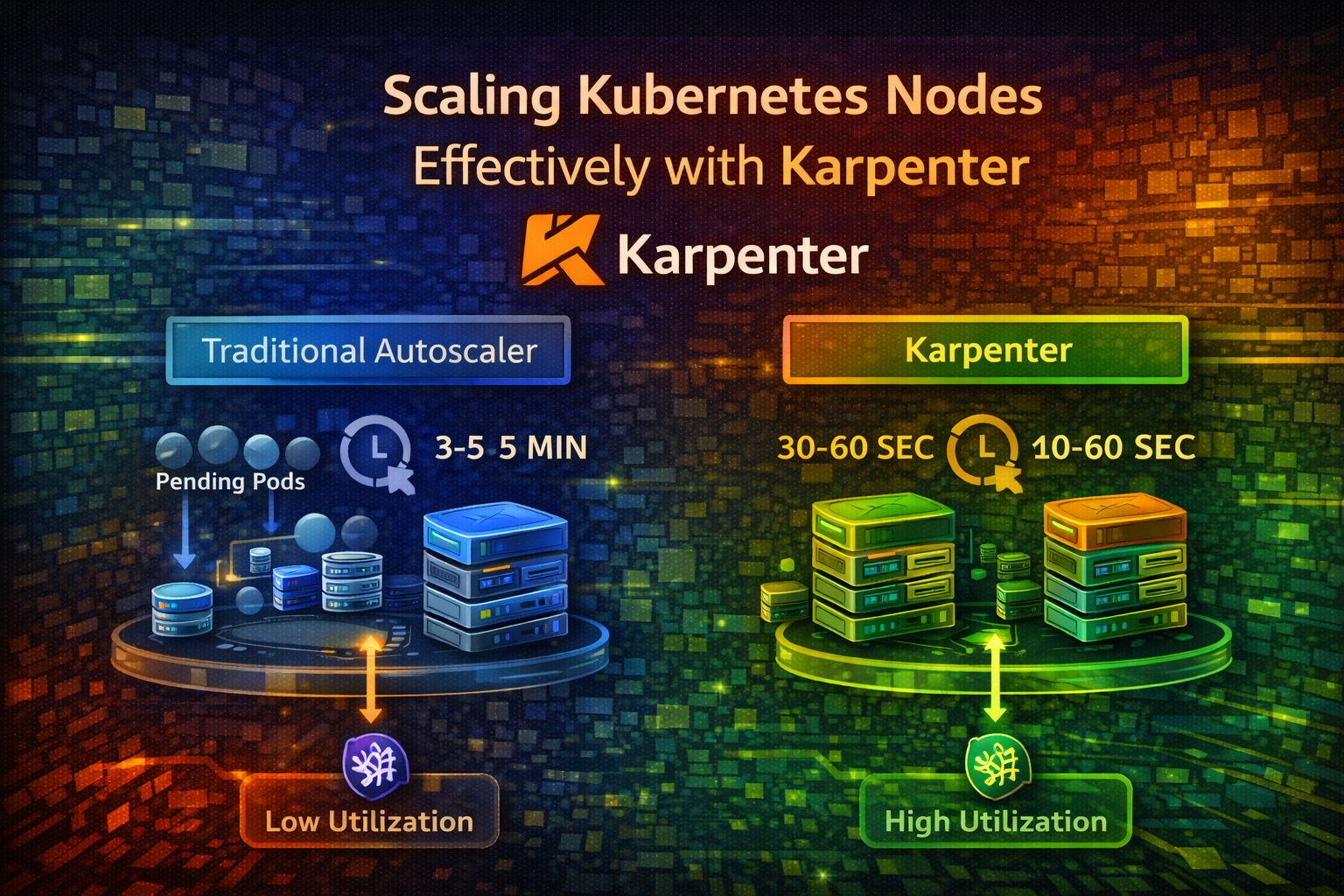
Cluster Kubernetes Anda berjalan lancar sampai deployment scale up dan tiba-tiba, pods stuck di state Pending. Tidak ada cukup nodes untuk menjalankan mereka. Anda menunggu cluster autoscaler untuk notice, provision nodes baru, dan boot mereka. Ini memakan waktu 3-5 menit. Pengguna Anda menunggu.
Sementara itu, Anda memiliki nodes lain berjalan pada 10% utilization, membuang uang. Cluster autoscaler tidak consolidate mereka karena conservative—tidak ingin disrupt workloads.
Karpenter menyelesaikan kedua masalah. Ini provision nodes dalam hitungan detik alih-alih menit dan actively consolidate underutilized nodes, mengurangi costs sebesar 30-50% dibandingkan traditional autoscalers.
Dalam artikel ini, kami akan mengeksplorasi mengapa node scaling penting, cara kerja Karpenter, dan cara mengimplementasikannya untuk cluster Anda.
#Masalah dengan Traditional Cluster Autoscalers
#Cara Kerja Cluster Autoscaler
Kubernetes' default cluster autoscaler mengawasi pending pods dan provision nodes baru. Berikut alurnya:
- Pod dibuat tetapi tidak bisa di-schedule (tidak ada nodes dengan capacity)
- Cluster autoscaler mendeteksi pending pods
- Autoscaler provision node baru dari cloud provider Anda
- Node boot dan join cluster (3-5 menit)
- Pod di-schedule di node baru
Ini bekerja, tetapi lambat dan tidak efisien.
#Masalah Inefficiency
Cluster autoscaler memiliki beberapa keterbatasan:
Slow Provisioning: Nodes memakan waktu 3-5 menit untuk boot. Selama waktu ini, pods menunggu dan pengguna mengalami latency.
Poor Consolidation: Cluster autoscaler jarang menghapus nodes. Ini conservative karena menghapus node mungkin disrupt workloads. Result: underutilized nodes membuang uang.
Bin Packing Issues: Cluster autoscaler tidak optimize bagaimana pods di-pack ke nodes. Anda mungkin memiliki 10 nodes pada 40% utilization alih-alih 7 nodes pada 60% utilization.
Limited Node Types: Cluster autoscaler bekerja dengan node groups yang Anda pre-define. Jika Anda memerlukan node type berbeda, Anda harus manually membuat node group baru.
No Cost Optimization: Cluster autoscaler tidak consider node costs. Ini mungkin provision expensive nodes ketika cheaper options ada.
#Real-World Impact
Pertimbangkan skenario typical:
- Anda memiliki 10 nodes berjalan pada 30% average utilization
- Monthly cost: $5,000 (assuming $500/node)
- Cluster autoscaler tidak consolidate karena conservative
- Anda membuang $3,500/bulan pada underutilized capacity
Dengan Karpenter, Anda mungkin consolidate ke 7 nodes pada 45% utilization, menghemat $1,500/bulan. Selama setahun, itu $18,000 dalam savings.
#Cara Kerja Karpenter
#Arsitektur Karpenter
Karpenter adalah node autoscaler yang dibangun untuk Kubernetes. Ini mengawasi pending pods dan provision nodes dalam hitungan detik. Ini juga actively consolidate underutilized nodes.
Berikut alurnya:
- Pod Pending: Pod tidak bisa di-schedule karena insufficient capacity
- Karpenter Detects: Karpenter's controller mengawasi pending pods
- Node Provisioning: Karpenter provision node dari cloud provider Anda (AWS, Azure, GCP)
- Fast Boot: Nodes boot dalam 30-60 detik (vs 3-5 menit untuk traditional autoscalers)
- Pod Scheduled: Pod di-schedule di node baru
- Consolidation: Karpenter continuously monitor node utilization dan remove underutilized nodes
Karpenter fundamentally berbeda dari cluster autoscaler: ini proactive, bukan reactive.
#Karpenter vs Cluster Autoscaler
| Aspek | Cluster Autoscaler | Karpenter |
|---|---|---|
| Provisioning Speed | 3-5 menit | 30-60 detik |
| Consolidation | Rare, conservative | Aggressive, continuous |
| Node Type Selection | Pre-defined groups | Dynamic, cost-optimized |
| Cost Optimization | Tidak | Ya |
| Bin Packing | Basic | Advanced |
| Multi-Cloud | Limited | AWS, Azure, GCP |
Karpenter dirancang untuk modern, dynamic workloads di mana speed dan cost penting.
#Konsep Fundamental
#Provisioners
Provisioner adalah resource Karpenter yang mendefinisikan bagaimana nodes harus di-provision. Ini menentukan:
- Cloud provider mana yang akan digunakan
- Node types dan sizes untuk dipertimbangkan
- Constraints (CPU, memory, zones, dll.)
- Consolidation behavior
- TTL (time to live) untuk nodes
Pikirkan Provisioner sebagai template untuk node creation.
#Consolidation
Consolidation adalah Karpenter's killer feature. Ini continuously monitor node utilization dan remove underutilized nodes dengan:
- Mengidentifikasi nodes yang underutilized
- Evicting pods dari nodes tersebut
- Scheduling pods di nodes lain
- Menghapus empty nodes
Ini terjadi secara otomatis dan continuously, keeping cluster Anda lean.
#Deprovisioning
Deprovisioning adalah proses menghapus nodes. Karpenter deprovision nodes ketika:
- Mereka underutilized (consolidation)
- Mereka exceeded TTL mereka (time to live)
- Mereka empty dan tidak dibutuhkan
- Node type yang lebih cost-effective tersedia
#Drift
Drift terjadi ketika konfigurasi node tidak match Provisioner's specification. Sebagai contoh, jika Anda update Provisioner untuk menggunakan instance type berbeda, existing nodes sekarang "drifted." Karpenter bisa automatically replace drifted nodes.
#Memulai: Basic Setup
#Prerequisites
- Kubernetes 1.19+ cluster
- AWS, Azure, atau GCP account
- Helm installed
- kubectl configured
#Install Karpenter
Install Karpenter menggunakan Helm:
helm repo add karpenter https://charts.karpenter.sh
helm repo updateBuat namespace dan install Karpenter:
kubectl create namespace karpenter
helm install karpenter karpenter/karpenter \
--namespace karpenter \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=arn:aws:iam::ACCOUNT_ID:role/KarpenterControllerRole \
--set settings.aws.clusterName=my-clusterImportant
Karpenter memerlukan IAM permissions untuk provision nodes. Setup KarpenterControllerRole dengan appropriate permissions sebelum installing.
Verifikasi Karpenter berjalan:
kubectl get pods -n karpenter
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter -f#Buat Provisioner
Provisioner memberitahu Karpenter bagaimana provision nodes. Berikut contoh basic:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
# Requirements untuk nodes
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "t3.xlarge"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a", "us-east-1b"]
# Consolidation settings
consolidation:
enabled: true
# TTL untuk nodes (24 jam)
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 86400
# Limits
limits:
resources:
cpu: 1000
memory: 1000Gi
# Provider (AWS)
provider:
subnetName: my-subnet
securityGroupName: my-security-group
tags:
Environment: productionProvisioner ini:
- Menggunakan on-demand instances (bukan spot)
- Provision t3 instances (medium, large, xlarge)
- Mengaktifkan consolidation
- Menghapus empty nodes setelah 30 detik
- Menghapus nodes setelah 24 jam (forces refresh)
- Membatasi total resources ke 1000 CPU dan 1000Gi memory
#Deploy Test Workload
Buat deployment untuk test Karpenter:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app
spec:
replicas: 5
selector:
matchLabels:
app: test-app
template:
metadata:
labels:
app: test-app
spec:
containers:
- name: app
image: nginx:latest
resources:
requests:
cpu: 500m
memory: 256Mi
limits:
cpu: 1000m
memory: 512MiDeploy:
kubectl apply -f test-app.yamlAmati Karpenter provision nodes:
kubectl get nodes --watch
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter -fAnda seharusnya melihat nodes baru di-provision dalam 30-60 detik. Jauh lebih cepat dari cluster autoscaler.
#Skenario Praktis
#Skenario 1: Cost Optimization dengan Spot Instances
Gunakan cheaper spot instances untuk non-critical workloads:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: spot
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "m5.large", "m5.xlarge"]
consolidation:
enabled: true
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 604800
provider:
subnetName: my-subnet
securityGroupName: my-security-groupProvisioner ini prefer spot instances (cheaper) tetapi fallback ke on-demand jika spot tidak tersedia. Karpenter automatically handle spot interruptions dengan evicting pods dan rescheduling mereka.
#Skenario 2: Multiple Provisioners untuk Different Workloads
Buat separate Provisioners untuk different workload types:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge"]
- key: karpenter.k8s.aws/instance-gpu-count
operator: In
values: ["1", "2"]
consolidation:
enabled: false
ttlSecondsAfterEmpty: 30
provider:
subnetName: my-subnet
securityGroupName: my-security-group
tags:
WorkloadType: gpuProvisioner ini handle GPU workloads. Pods requesting GPUs di-schedule di GPU nodes. CPU-only pods menggunakan default Provisioner.
#Skenario 3: Zone Distribution
Spread nodes across multiple zones untuk high availability:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: multi-zone
spec:
requirements:
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a", "us-east-1b", "us-east-1c"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large"]
consolidation:
enabled: true
ttlSecondsAfterEmpty: 30
provider:
subnetName: my-subnet
securityGroupName: my-security-groupKarpenter distribute nodes across zones, meningkatkan fault tolerance.
#Skenario 4: Consolidation Tuning
Kontrol seberapa agresif Karpenter consolidate nodes:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: aggressive-consolidation
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["t3.medium", "t3.large", "t3.xlarge"]
consolidation:
enabled: true
# Hapus empty nodes immediately
ttlSecondsAfterEmpty: 0
# Refresh nodes setiap 7 hari
ttlSecondsUntilExpired: 604800
provider:
subnetName: my-subnet
securityGroupName: my-security-groupIni aggressively consolidate nodes, menghapus empty nodes immediately. Gunakan ini untuk cost-sensitive environments.
#Advanced Configuration
#Pod Disruption Budgets
Lindungi critical workloads selama consolidation:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: critical-app-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: critical-appIni memastikan at least 2 pods dari critical-app selalu berjalan. Karpenter tidak akan consolidate nodes jika ini akan violate budget ini.
#Taints dan Tolerations
Gunakan taints untuk restrict pods mana yang bisa berjalan di certain nodes:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: batch-processing
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["c5.large", "c5.xlarge"]
taints:
- key: workload-type
value: batch
effect: NoSchedule
consolidation:
enabled: true
provider:
subnetName: my-subnet
securityGroupName: my-security-groupHanya pods dengan matching tolerations bisa berjalan di nodes ini:
apiVersion: v1
kind: Pod
metadata:
name: batch-job
spec:
tolerations:
- key: workload-type
operator: Equal
value: batch
effect: NoSchedule
containers:
- name: job
image: batch-processor:latest#Monitoring Karpenter
Monitor Karpenter's behavior dengan Prometheus metrics:
# Nodes di-provision
increase(karpenter_nodes_allocatable[5m])
# Nodes di-consolidate
increase(karpenter_nodes_consolidated[5m])
# Pending pods
karpenter_pods_pending
# Provisioning duration
histogram_quantile(0.99, rate(karpenter_provisioning_duration_seconds_bucket[5m]))Setup dashboards untuk visualize metrics ini.
#Kesalahan Umum dan Pitfalls
#Kesalahan 1: Tidak Setting Resource Requests
Jika pods tidak memiliki resource requests, Karpenter tidak bisa calculate node capacity. Pods mungkin di-schedule di nodes yang tidak memiliki cukup resources.
Lebih Baik: Selalu set resource requests dan limits:
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi#Kesalahan 2: Mengabaikan Pod Disruption Budgets
Tanpa PodDisruptionBudgets, Karpenter mungkin consolidate nodes dan disrupt critical workloads.
Lebih Baik: Definisikan PodDisruptionBudgets untuk critical applications.
#Kesalahan 3: Setting TTL Terlalu Rendah
Jika ttlSecondsUntilExpired terlalu rendah, nodes constantly di-replace, menyebabkan unnecessary disruption.
Lebih Baik: Set TTL ke 24-48 jam. Ini balance freshness dengan stability.
#Kesalahan 4: Over-Consolidating
Aggressive consolidation menghemat uang tetapi bisa menyebabkan latency spikes ketika pods di-evict dan di-reschedule.
Lebih Baik: Tune consolidation berdasarkan workload Anda. Untuk latency-sensitive applications, lebih conservative.
#Kesalahan 5: Tidak Monitoring Karpenter
Karpenter adalah komponen lain yang bisa fail. Jika crash, node scaling berhenti.
Lebih Baik: Monitor Karpenter's health, setup alerts, dan pastikan highly available.
#Best Practices
#1. Mulai dengan Conservative Settings
Jangan enable aggressive consolidation immediately. Mulai dengan:
consolidation:
enabled: true
ttlSecondsAfterEmpty: 300
ttlSecondsUntilExpired: 604800Monitor behavior dan adjust berdasarkan real-world results.
#2. Gunakan Multiple Provisioners
Buat separate Provisioners untuk different workload types:
- General workloads (default)
- GPU workloads
- Batch processing
- Memory-intensive workloads
Ini memberikan Anda fine-grained control atas node provisioning.
#3. Kombinasikan dengan Pod Disruption Budgets
Lindungi critical workloads dengan PodDisruptionBudgets. Ini mencegah Karpenter dari disrupting mereka selama consolidation.
#4. Monitor Cost Savings
Track berapa banyak Anda menghemat dengan Karpenter:
# Sebelum Karpenter: 10 nodes × $500/bulan = $5,000
# Setelah Karpenter: 7 nodes × $500/bulan = $3,500
# Savings: $1,500/bulan = $18,000/tahun#5. Test Consolidation Behavior
Sebelum deploy ke production, test bagaimana Karpenter consolidate nodes:
- Deploy workloads dan amati nodes scale up
- Hapus workloads dan amati nodes consolidate
- Verifikasi pods tidak di-disrupt unexpectedly
#6. Gunakan Spot Instances untuk Non-Critical Workloads
Spot instances 70-90% lebih murah dari on-demand. Gunakan untuk:
- Batch processing
- Development/testing
- Non-critical background jobs
Karpenter handle spot interruptions secara otomatis.
#7. Set Resource Limits
Cegah runaway provisioning dengan setting limits:
limits:
resources:
cpu: 1000
memory: 1000GiIni mencegah Karpenter dari provisioning lebih dari 1000 CPU cores atau 1000Gi memory.
#Kapan TIDAK Menggunakan Karpenter
#Karpenter Tidak Ideal Ketika:
- Anda memiliki small, static cluster: Karpenter's benefits paling visible dengan dynamic workloads
- Anda memerlukan guaranteed node types: Karpenter dynamically select node types; jika Anda memerlukan specific hardware, gunakan traditional autoscalers
- Anda tidak di AWS, Azure, atau GCP: Karpenter support clouds ini; platforms lain memerlukan different solutions
- Anda memiliki very strict compliance requirements: Karpenter's dynamic provisioning mungkin tidak fit rigid compliance frameworks
#Kesimpulan
Karpenter mentransformasi cara Anda scale Kubernetes clusters. Alih-alih menunggu 3-5 menit untuk nodes boot, Anda mendapatkan nodes dalam 30-60 detik. Alih-alih membuang uang di underutilized nodes, Karpenter actively consolidate mereka.
Insight fundamental: node scaling harus fast, efficient, dan cost-aware. Karpenter deliver ketiga-tiganya.
Mulai dengan basic Provisioner untuk general workloads. Tambahkan specialized Provisioners untuk GPU, batch processing, atau other workload types. Aktifkan consolidation dan amati costs Anda drop. Monitor semuanya dan adjust berdasarkan real-world behavior.
Cluster Anda akan lebih cepat, lebih murah, dan lebih efisien.
#Langkah Selanjutnya
- Install Karpenter di Kubernetes cluster Anda
- Buat basic Provisioner untuk general workloads
- Deploy test workloads dan amati nodes scale
- Monitor consolidation dan verifikasi pods tidak di-disrupt
- Tambahkan specialized Provisioners untuk different workload types
- Track cost savings dan celebrate wins
Mulai simple, test thoroughly, dan scale intelligently.