Dari Data Warehouse ke Modern Data Lakehouse - Evolusi Arsitektur & Separation of Concern
Jelajahi evolusi dari traditional data warehouse ke modern data lakehouse. Pelajari bagaimana decoupled storage, open table format, dan query engine mentransformasi data architecture dengan Apache Iceberg, Nessie, dan S3-based storage.

#Pengenalan
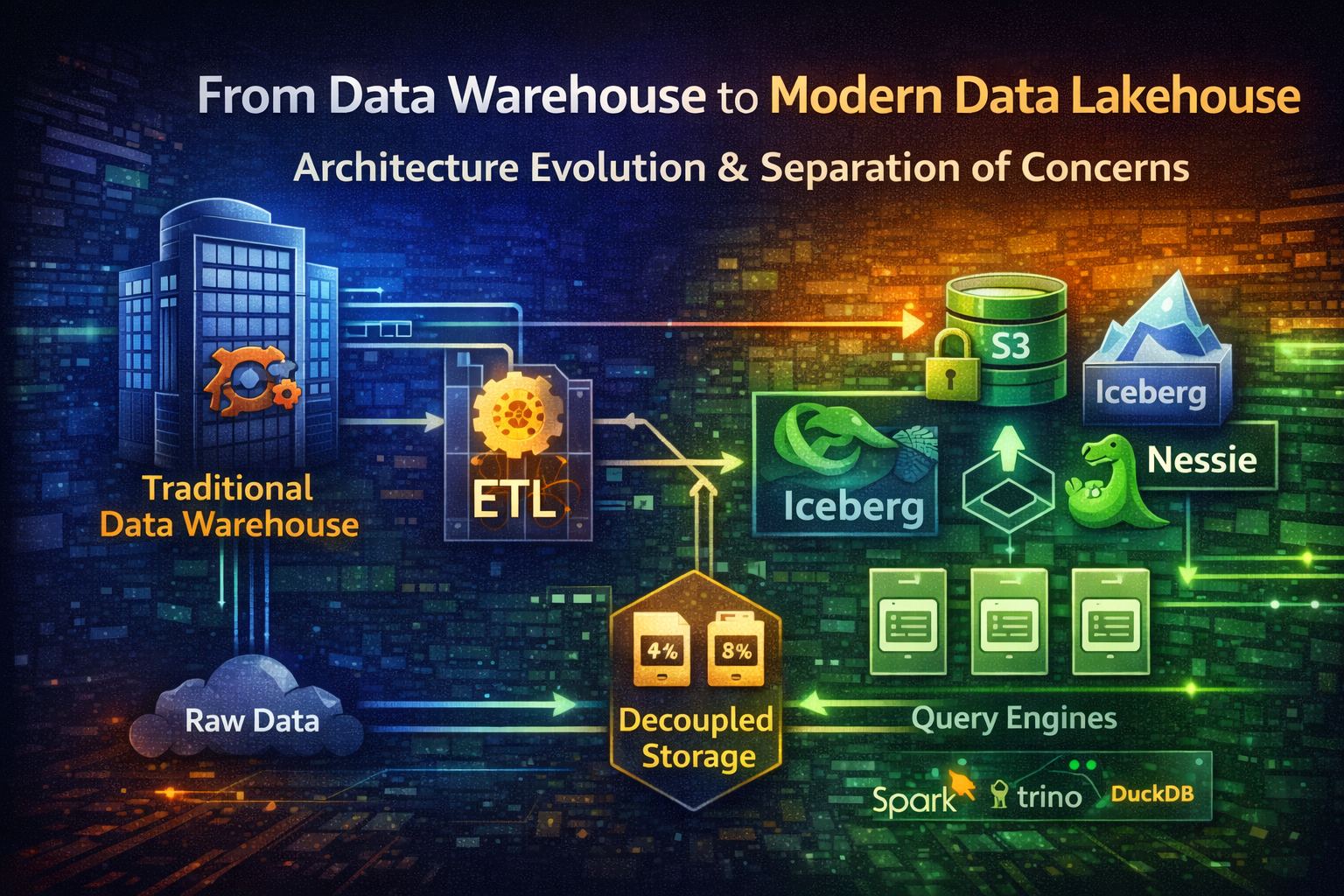
Data architecture telah mengalami transformasi fundamental selama dekade terakhir. Traditional data warehouse—sistem monolithic yang tightly coupled dan dioptimalkan untuk structured analytics—memberikan jalan kepada modern data lakehouse: arsitektur cloud-native yang decoupled yang memisahkan storage, compute, dan metadata management.
Shift ini bukan hanya tentang pilihan teknologi. Ini tentang rethinking bagaimana data mengalir melalui organisasi. Alih-alih memaksa semua data ke rigid schema sebelum storage, modern lakehouse menyimpan raw data dalam open format, menerapkan schema-on-read logic, dan membiarkan multiple query engine beroperasi independently pada data yang sama.
Dalam panduan ini, kami akan melacak evolusi dari classic data warehouse ke modern lakehouse, memahami mengapa separation of concern penting, dan jelajahi teknologi yang memungkinkan transformasi ini.
#Classic Data Warehouse: Tightly Coupled Architecture
#Bagaimana Traditional Data Warehouse Bekerja
Classic data warehouse seperti Teradata, Netezza, atau on-premises Redshift mengikuti monolithic design:
Raw Data → ETL (Extract, Transform, Load) → Warehouse Storage → Query Engine → AnalyticsSemuanya terintegrasi ke dalam satu sistem:
- Storage: Proprietary columnar format, tightly coupled ke query engine
- Compute: Fixed resource dialokasikan ke warehouse
- Metadata: Dikelola internally oleh warehouse
- Query Engine: Single SQL runtime, dioptimalkan untuk warehouse storage format
#Karakteristik Traditional Warehouse
Kekuatan:
- Predictable performance untuk structured query
- Strong ACID guarantee
- Mature tooling dan operational practice
- Schema-on-write memastikan data quality upfront
Keterbatasan:
- Expensive untuk scale (compute dan storage bundled)
- Sulit support multiple query pattern (SQL, ML, streaming)
- Vendor lock-in dengan proprietary format
- Slow untuk adapt ke new data type (unstructured, semi-structured)
- ETL bottleneck selama data ingestion
#ETL Bottleneck
Traditional ETL pipeline rigid dan resource-intensive:
Data Source → Transformation Logic → Validation → Load to WarehouseSetiap data change memerlukan:
- Extract dari source system
- Transform ke warehouse schema
- Validate terhadap business rule
- Load ke warehouse storage
Proses ini slow, expensive, dan membuat single point of failure. Jika transformation logic berubah, Anda harus re-process historical data.
#Data Lake Experiment: Storage Tanpa Structure
Di awal 2010-an, organisasi mencoba pendekatan berbeda: dump semuanya ke cheap object storage (S3, HDFS) dan figure out structure nanti.
Raw Data → S3 (Parquet/ORC) → Spark/Hadoop → AnalyticsJanji: Unlimited scalability, schema-on-read flexibility, lower cost.
Realitas: Data swamp.
Tanpa structure, data lake menjadi:
- Sulit discover (data apa yang ada?)
- Sulit govern (siapa yang own apa?)
- Slow untuk query (tidak ada optimization)
- Unreliable (tidak ada ACID guarantee)
- Fragmented (multiple incompatible format)
Data lake menyelesaikan storage problem tetapi membuat problem baru di sekitar metadata, governance, dan query performance.
#Modern Data Lakehouse: Separation of Concern
Modern data lakehouse menggabungkan best of both world: scalability dan flexibility dari data lake dengan structure dan reliability dari data warehouse.
Inovasi kunci: decoupling storage, compute, dan metadata.
┌─────────────────────────────────────────────────────────────┐
│ Query Layer │
│ (Trino, Spark, DuckDB, Presto, Athena) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Open Table Format Layer │
│ (Apache Iceberg, Delta Lake, Apache Hudi) │
│ + Metadata Management (Nessie, Polaris) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Storage Layer │
│ (S3, GCS, Azure Blob Storage) │
│ Format: Parquet, Avro, ORC │
└─────────────────────────────────────────────────────────────┘#Layer 1: Storage (Decoupled)
Modern lakehouse menggunakan cloud object storage sebagai foundation:
Mengapa S3 (atau equivalent)?
- Unlimited scalability
- Pay-per-use pricing
- Durability dan availability
- Bekerja dengan any compute engine
Data Format:
# Parquet structure
[Row Group 1]
├── Column 1 (compressed)
├── Column 2 (compressed)
└── Column 3 (compressed)
[Row Group 2]
├── Column 1 (compressed)
├── Column 2 (compressed)
└── Column 3 (compressed)Parquet adalah columnar, compressed, dan schema-aware. Perfect untuk analytics.
# Avro structure
{
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": "string"}
]
}Avro adalah row-based, schema-versioned, dan ideal untuk streaming dan event data.
Kedua format adalah open, language-agnostic, dan supported oleh multiple tool.
#Layer 2: Open Table Format (Metadata Management)
Raw Parquet file dalam S3 kekurangan structure. Open table format menambahkan missing layer: metadata management, ACID transaction, dan schema evolution.
#Apache Iceberg
Iceberg adalah table format yang sits on top of object storage:
S3 Bucket
├── data/
│ ├── 00001-abc.parquet
│ ├── 00002-def.parquet
│ └── 00003-ghi.parquet
├── metadata/
│ ├── v1.metadata.json
│ ├── v2.metadata.json
│ └── snap-123.avro
└── metadata.json (current version pointer)Iceberg track:
- Schema evolution
- Snapshot (version dari table)
- Partition information
- File statistic
- Transaction history
Contoh: Membuat Iceberg table
CREATE TABLE users (
id INT,
name STRING,
email STRING,
created_at TIMESTAMP
)
USING iceberg
PARTITIONED BY (year(created_at))
LOCATION 's3://my-bucket/users';Time Travel: Query Historical Data
-- Query table seperti 1 jam yang lalu
SELECT * FROM users
FOR SYSTEM_TIME AS OF timestamp_sub(now(), interval 1 hour);
-- Query specific snapshot
SELECT * FROM users
VERSION AS OF 'snapshot-id-123';Ini powerful untuk debugging, auditing, dan recovery.
#Nessie: Git-Like Version Control untuk Data
Nessie menambahkan Git-like semantic ke data table:
Main Branch
├── Commit 1: "Add user table"
├── Commit 2: "Add email column"
└── Commit 3: "Fix data quality issue"
Feature Branch (dev)
├── Commit 1: "Add phone column"
└── Commit 2: "Update schema"Mengapa Git-like versioning untuk data?
- Branch: Experiment dengan schema change tanpa mempengaruhi production
- Commit: Track siapa yang ubah apa dan kapan
- Merge: Combine change dari multiple branch
- Rollback: Revert ke previous state jika sesuatu break
Contoh: Nessie dengan Iceberg
# Buat feature branch
nessie branch create feature/add-phone-column
# Switch ke branch
nessie checkout feature/add-phone-column
# Buat change (add column, update data)
# Commit change
nessie commit -m "Add phone column to users table"
# Merge kembali ke main
nessie checkout main
nessie merge feature/add-phone-columnIni memungkinkan data team untuk bekerja seperti software engineer: experiment safely, review change, dan merge dengan confidence.
#Layer 3: Query Engine (Decoupled Compute)
Lakehouse tidak mandate single query engine. Multiple engine dapat query data yang sama:
Apache Iceberg Tables dalam S3
├── Trino (distributed SQL)
├── Spark (batch & streaming)
├── DuckDB (analytical query)
├── Presto (interactive query)
└── Athena (serverless SQL)Setiap engine memiliki strength berbeda:
- Trino: Distributed SQL di multiple data source
- Spark: Large-scale batch processing dan ML
- DuckDB: Fast analytical query pada single machine
- Athena: Serverless, pay-per-query model
- Flink: Real-time streaming analytics
Contoh: Data yang sama, engine berbeda
-- Trino: Interactive query
SELECT user_id, COUNT(*) as events
FROM events
WHERE date >= '2026-01-01'
GROUP BY user_id
LIMIT 100;# Spark: Batch processing
df = spark.read.format("iceberg").load("s3://bucket/events")
result = df.filter(col("date") >= "2026-01-01") \
.groupBy("user_id") \
.count() \
.limit(100)
result.show()-- DuckDB: Local analytical query
SELECT user_id, COUNT(*) as events
FROM read_parquet('s3://bucket/events/*.parquet')
WHERE date >= '2026-01-01'
GROUP BY user_id
LIMIT 100;Data yang sama, tool berbeda untuk use case berbeda.
#Separation of Concern: Mengapa Penting
#1. Storage & Compute Decoupling
Traditional warehouse:
Compute Resource (Fixed)
↓
Storage (Bundled)Anda bayar untuk compute bahkan ketika idle. Scaling memerlukan provisioning lebih banyak resource.
Modern lakehouse:
Compute Resource (Elastic)
↓
Storage (Shared)
↓
Multiple Query EngineScale compute independently dari storage. Bayar hanya untuk apa yang Anda gunakan.
#2. Multiple Query Pattern
Traditional warehouse: One SQL engine, one way untuk query.
Modern lakehouse: Pilih tool yang tepat untuk job.
Data Scientist → Spark (ML, Python)
Analytics Team → Trino (Interactive SQL)
Real-time Dashboard → Flink (Streaming)
Ad-hoc Query → DuckDB (Local)#3. Schema Evolution Tanpa Reprocessing
Traditional warehouse: Schema change memerlukan ETL reprocessing.
Modern lakehouse: Iceberg handle schema evolution secara transparent.
-- Tambahkan column baru
ALTER TABLE users ADD COLUMN phone STRING;
-- Old data automatically memiliki NULL untuk phone
-- New data include phone value
-- Tidak ada reprocessing yang diperlukan#4. Data Governance & Lineage
Nessie menyediakan Git-like audit trail:
nessie log --table users
# Menunjukkan siapa yang ubah apa, kapan, dan mengapaIni critical untuk compliance (GDPR, HIPAA) dan debugging.
#Modern ETL: Dari Batch ke Streaming
#Traditional ETL: Batch-Oriented
Scheduled Job → Extract → Transform → Load → WarehouseBerjalan nightly, process semua data, update warehouse.
Problem:
- Latency (data berusia jam)
- Resource spike selama batch window
- Sulit handle late-arriving data
- All-or-nothing: jika transformation gagal, entire batch gagal
#Modern ELT: Extract, Load, Transform
Data Source → S3 (Raw) → Transform (On-Demand) → AnalyticsLoad raw data terlebih dahulu, transform nanti.
Benefit:
- Lower latency (data tersedia immediately)
- Flexible transformation (ubah logic tanpa reprocessing)
- Resilient (raw data preserved)
- Support streaming dan batch
#UI-Based ETL: Apache NiFi
Untuk team tanpa strong engineering resource, UI-based ETL tool seperti Apache NiFi menyediakan visual data pipeline design:
┌──────────────┐
│ Data Source │
└──────┬───────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Extract) │
└──────┬───────────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Transform) │
└──────┬───────────┘
│
↓
┌──────────────────┐
│ NiFi Processor │
│ (Load to S3) │
└──────────────────┘NiFi advantage:
- Visual pipeline design (tidak perlu coding)
- Built-in error handling dan retry logic
- Data provenance tracking
- Support multiple data source dan format
- Scale horizontally
Contoh: NiFi Flow
GetFile (Baca dari /data)
↓
UpdateAttribute (Tambahkan metadata)
↓
ConvertRecord (CSV → Parquet)
↓
PutS3Object (Tulis ke S3)
↓
PublishKafka (Notifikasi downstream)Setiap processor adalah reusable component. Chain mereka bersama untuk build complex pipeline tanpa code.
#Real-World Architecture: Menyatukan Semuanya
Berikut adalah complete modern lakehouse architecture:
┌─────────────────────────────────────────────────────────────┐
│ Data Source │
│ (Database, API, Log, Streaming) │
└────────────────────┬────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────────┐
│ Ingestion Layer (NiFi) │
│ • Extract dari source │
│ • Minimal transformation │
│ • Load ke S3 (raw zone) │
└────────────────────┬────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────────┐
│ Storage Layer (S3) │
│ • Raw Zone (Parquet/Avro) │
│ • Processed Zone (Iceberg Table) │
│ • Curated Zone (Business-ready table) │
└────────────────────┬────────────────────────────────────────┘
│
┌────────────┼────────────┐
↓ ↓ ↓
┌──────────────┐ ┌──────────┐ ┌──────────┐
│ Spark Job │ │ Trino │ │ DuckDB │
│ (Batch) │ │ (SQL) │ │ (Local) │
└──────┬───────┘ └────┬─────┘ └────┬─────┘
│ │ │
└──────────────┼────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Metadata Layer (Nessie + Iceberg) │
│ • Schema management │
│ • Version control │
│ • Time travel query │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Analytics & BI │
│ (Dashboard, Report, ML Model) │
└─────────────────────────────────────────────────────────────┘#Kesalahan & Jebakan Umum
#Kesalahan 1: Memperlakukan Lakehouse Seperti Data Lake
Masalahnya: Dump data ke S3 tanpa table format atau governance.
Mengapa terjadi: Team skip open table format layer untuk save complexity.
Cara menghindarinya:
- Gunakan Iceberg atau Delta Lake dari hari pertama
- Implementasikan schema validation
- Setup data governance policy
- Gunakan Nessie untuk version control
#Kesalahan 2: Mengabaikan Partition Strategy
Masalahnya: Query scan entire dataset, performance degrade.
Mengapa terjadi: Partition strategy adalah afterthought.
Cara menghindarinya:
- Partition oleh frequently filtered column (date, region, customer_id)
- Gunakan time-based partition untuk time-series data
- Monitor partition size (aim untuk 100MB-1GB per partition)
CREATE TABLE events (
event_id INT,
user_id INT,
event_type STRING,
timestamp TIMESTAMP
)
USING iceberg
PARTITIONED BY (year(timestamp), month(timestamp))
LOCATION 's3://bucket/events';#Kesalahan 3: Tidak Monitoring Query Performance
Masalahnya: Query slow down seiring waktu saat data berkembang.
Mengapa terjadi: Tidak ada performance monitoring atau optimization.
Cara menghindarinya:
- Monitor query execution time
- Track data skew (uneven partition size)
- Gunakan table statistic untuk query optimization
- Compact small file secara regular
#Kesalahan 4: Mencampur Raw dan Processed Data
Masalahnya: Raw data dimodifikasi, breaking downstream pipeline.
Mengapa terjadi: Tidak ada clear data zone atau governance.
Cara menghindarinya:
- Pisahkan raw, processed, dan curated zone
- Buat raw zone immutable
- Gunakan Iceberg snapshot untuk reproducibility
#Kesalahan 5: Underestimating Operational Complexity
Masalahnya: Lakehouse memerlukan lebih banyak operational expertise daripada traditional warehouse.
Mengapa terjadi: Team underestimate learning curve.
Cara menghindarinya:
- Invest dalam training dan documentation
- Mulai dengan pilot project
- Build runbook untuk common operation
- Monitor metadata layer health
#Best Practice untuk Modern Lakehouse
#1. Implementasikan Data Zone
s3://data-lake/
├── raw/ (Immutable, as-is dari source)
├── processed/ (Cleaned, validated, Iceberg table)
└── curated/ (Business-ready, optimized)Setiap zone memiliki governance rule dan access pattern berbeda.
#2. Gunakan Iceberg untuk Semua Table
-- Baik
CREATE TABLE users USING iceberg ...
-- Hindari
CREATE TABLE users USING parquet ...Iceberg menyediakan ACID guarantee, schema evolution, dan time travel.
#3. Implementasikan Schema Registry
{
"subject": "users-value",
"version": 1,
"schema": {
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"}
]
}
}Centralize schema management untuk prevent incompatibility.
#4. Monitor Data Quality
# Periksa untuk null dalam critical column
assert df.filter(col("user_id").isNull()).count() == 0
# Periksa untuk duplicate
assert df.count() == df.dropDuplicates(["user_id"]).count()
# Periksa untuk data freshness
latest_date = df.agg(max("created_at")).collect()[0][0]
assert (datetime.now() - latest_date).days < 1Automate data quality check dalam pipeline Anda.
#5. Gunakan Nessie untuk Experimentation
# Buat isolated branch untuk experiment
nessie branch create experiment/new-schema
# Buat change tanpa mempengaruhi production
# Test secara menyeluruh
# Merge hanya ketika confident
nessie merge experiment/new-schemaBranch memungkinkan safe experimentation dan rollback.
#Kapan Pilih Lakehouse vs. Traditional Warehouse
Pilih lakehouse jika:
- Anda perlu support multiple query pattern (SQL, ML, streaming)
- Data volume besar dan berkembang cepat
- Anda ingin avoid vendor lock-in
- Anda memerlukan schema flexibility
- Anda memiliki multi-cloud requirement
Pilih traditional warehouse jika:
- Data volume kecil (< 1TB)
- Anda memerlukan predictable performance
- Tim Anda kekurangan data engineering expertise
- Anda memiliki simple, structured analytics need
- Anda lebih suka managed service dengan minimal operation
#Kesimpulan
Shift dari traditional data warehouse ke modern lakehouse merepresentasikan fundamental rethinking dari data architecture. Dengan decoupling storage, compute, dan metadata, lakehouse menyediakan flexibility, scalability, dan cost efficiency yang monolithic warehouse tidak dapat match.
Teknologi kunci yang memungkinkan transformasi ini:
- Apache Iceberg: Open table format dengan ACID guarantee dan time travel
- Nessie: Git-like version control untuk data
- S3 + Parquet/Avro: Scalable, open storage format
- Multiple query engine: Pilih tool yang tepat untuk setiap workload
- Apache NiFi: Visual ETL untuk non-engineer
Perjalanan dari warehouse ke lakehouse bukan hanya technology upgrade—ini adalah shift menuju lebih flexible, collaborative, dan scalable data infrastructure. Mulai dengan pilot project, invest dalam team training, dan gradually migrate workload saat team Anda gain confidence.
Masa depan data architecture adalah decoupled, open, dan collaborative. Lakehouse sudah tiba.